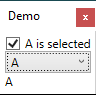
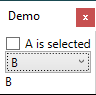
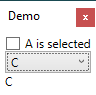
How to screenshot a WPF window: Original SO post here, my code here.
I recently needed to create a template for some documents (character sheets for a TRPG).
There are of course hundreds of ways to do this, using countless different programs.
I didn’t want to invest the time to learn one of the more applicable ones or tinker for hours with one that I know, but that isn’t intended for it.
Then I remembered: I’m already doing this kind of thing all the time. Only in those cases the template can be clicked on or typed in. Making a screenshot of those would give me a perfectly fine template.
The biggest question was of course, how to create a screenshot of a window? I could make it the classic way, but having the program take one itself would be much less work in the long run. And as I realized later, it’s the only way to create templates from windows that don’t fit on your screen (assuming you want to keep the quality high).
Taking the screenshot was done based on code from user “aloisdg” on SO (where else): https://stackoverflow.com/questions/30095895/take-a-screenshot-of-a-wpf-window-with-the-predefined-image-size-without-losing
You’ll find my adaption of the code below. For now let’s talk about some aspects of setting up the window.
Some initial values you should decide on are the background color and size of the window. Take advantage of the built-in, automatic conversions available in WPF. I had an exact size in pixels I wanted, but you can also use things like cm or in (the example below matches A4 paper).
And while not required, changing the style to None is helpful for designing.
MinHeight="29.7cm" MinWidth="21cm" MaxHeight="29.7cm" MaxWidth="21cm" Background="White" WindowStyle="None"
You might be wondering why I didn’t just set width and height directly. That might work for you, but in my case the rendering stopped at the edge of my screen or distorted the image. Limiting width and height in this manner was simply the easiest way to force a size.
The actual design of the UI is of course up to you. Don’t bother making “good UI”. The window you create doesn’t need to work, or be easy to maintain, just look a certain way. Grid and Rectangle are probably your best friends, but get creative.
<TextBox Text="Name" FontSize="0.35cm" Foreground="Gray" BorderThickness="2" BorderBrush="Black" Width="10cm" Height="1.5cm"/>

As you can see, a TextBox for example can look like a GroupBox with the label inside rather than on the line.
Now for the fun part: Making screenshots.
To do that we first have to change the build action of App.xaml to Page and remove the StartupUri. Now we can add a Main method in App.xaml.cs from which to trigger the screenshot.
Here’s what the code looks like for me:
[STAThread] public static void Main(string[] args) { MainWindow mainWindow = new MainWindow(); mainWindow.Show(); using (FileStream fileStream = new FileStream("Screenshot.png", FileMode.Create, FileAccess.Write, FileShare.None)) DrawWindow(mainWindow, fileStream); } static void DrawWindow(Window window, Stream targetStream) { DrawingVisual drawingVisual = new DrawingVisual(); using (DrawingContext drawingContext = drawingVisual.RenderOpen()) drawingContext.DrawRectangle(new VisualBrush(window), null, new Rect(new Point(), new Size(window.Width, window.Height))); RenderTargetBitmap renderTargetBitmap = new RenderTargetBitmap((int)window.Width, (int)window.Height, 96, 96, PixelFormats.Pbgra32); renderTargetBitmap.Render(drawingVisual); PngBitmapEncoder pngBitmapEncoder = new PngBitmapEncoder(); pngBitmapEncoder.Frames.Add(BitmapFrame.Create(renderTargetBitmap)); pngBitmapEncoder.Save(targetStream); }
Instead of using a Main method you could probably just add the screenshot code in the windows load event.